



Web application architecture defines the interactions between applications, middle-ware systems and databases to ensure multiple applications can work together.When a user types in a URL and taps “Go,” the browser will find where on the internet the website lives on and requests that particular page. The server then responds by sending files over to the browser. The browser executes those files to show the requested page to the user. All these actions are executed within a matter of seconds.
What’s important here is the code, which has been parsed by the browser. This code may or may not have specific instructions telling the browser how to react to a wide range of inputs.
As a result, web application architecture basics include all sub-components and external application interchanges for an entire software application. It deals with scale, efficiency, robustness, and security.
Web application architecture is critical since the majority of global network traffic, and every single app and device uses web-based communication.
The above diagram is a fairly good representation of typical web architecture. Let’s take a walkthrough of the different components that make it work.
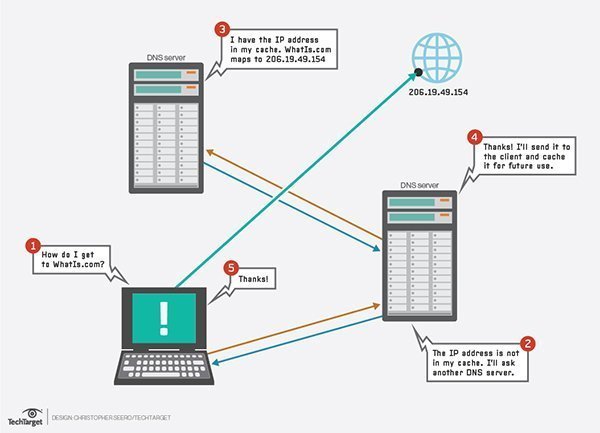
1. DNS
The domain name system (DNS) is the way that internet domain names are located and translated into internet protocol (IP) addresses. The domain name system maps the name people use to locate a website to the IP address that a computer uses to locate a website.
For example, if someone types appscrip.com into a web browser, a server behind the scenes will map that name to an IP address, which could be something like this – 206.19.49.149
2. Load Balancer
Load balancing refers to efficiently distributing incoming network traffic across a group of backend servers, also known as a server farm or server pool.
Modern high-traffic websites must serve hundreds of thousands, if not millions, of concurrent requests from users or clients and return the correct text, images, video, or application data, all in a fast and reliable manner.
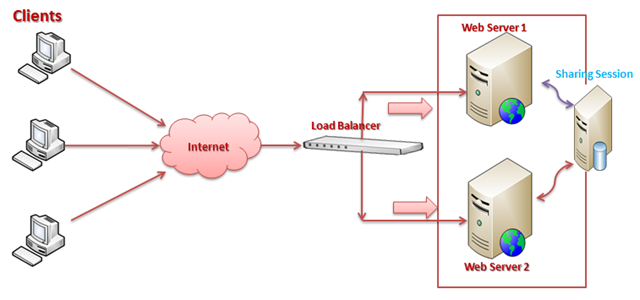
A load balancer acts as the traffic cop sitting in front of your servers and routing client requests across all servers capable of fulfilling those requests in a manner that maximizes speed and capacity utilization and ensures that no one server is overworked, which could degrade performance. If a single server goes down, the load balancer redirects traffic to the remaining online servers. When a new server is added to the server group, the load balancer automatically starts to send requests to it.
In this manner, a load balancer performs the following functions:
- Distributes client requests or network load efficiently across multiple servers
- Ensures high availability and reliability by sending requests only to servers that are online
- Provides the flexibility to add or subtract servers as demand dictates
3. Web Application Servers
At a high level, web application servers execute the core business logic that handles a user’s request and sends back HTML to the user’s browser. To do their job, they typically communicate with a variety of backend infrastructure such as databases, caching layers, job queues, search services, other microservices, data/logging queues, and more.
App server implementations require choosing a specific language (Node.js, Ruby, PHP, Scala, Java, C# .NET) and a web MVC framework for that language (Express for Node.js, Ruby on Rails, Play for Scala, Laravel for PHP)
4. Database Servers
A database server is a computer system that provides other computers with services related to accessing and retrieving data from a database. Access to the database server may occur via a “front end” running locally a user’s machine or “back end” running on the database server itself, accessed by remote shell. After the information in the database is retrieved, it is outputted to the user requesting the data.
Many companies utilize a database server for storage. Users can access the data by executing a query using a query language specific to the database. For example, SQL (Structured Query Language)
The Database server controls and manages all the clients that are connected to it. It handles all database access and control functions.
5. Caching Service
A cache is a memory buffer used to temporarily store frequently accessed data. It improves performance since data does not have to be retrieved again from the original source.
Devices such as routers, switches, and PCs use caching to speed up memory access. Another very common cache, used on almost all PCs, is the web browser cache for storing requested objects so that the same data doesn’t need to be retrieved multiple times.
In a distributed JEE application, the client/server side cache plays a significant role in improving application performance. The client-side cache is used to temporarily store the static data transmitted over the network from the server to avoid unnecessarily calling to the server. The server-side cache is used to store data in memory fetched from other resources.
The two most widespread caching server technologies are Redis and Memcached.
[spacer height=”5px”][adrotate banner=”7″][spacer height=”5px”]
6. Job Queue & Servers
Most web applications need to do some work asynchronously behind the scenes that’s not directly associated with responding to a user’s request. For instance, Google needs to crawl and index the entire internet in order to return search results. It does not do this every time you search. Instead, it crawls the web asynchronously, updating the search indexes along the way.
The ‘job queue’ architecture consists of two components: a queue of ‘jobs’ that need to be run and one or more job servers that run the jobs in the queue.
Job queues store a list of jobs that need to be run asynchronously. The simplest are first-in-first-out (FIFO) queues though most applications end up needing some sort of priority queuing system. Whenever the app needs a job to be run, either on some sort of regular schedule or as determined by user actions, it simply adds the appropriate job to the queue.
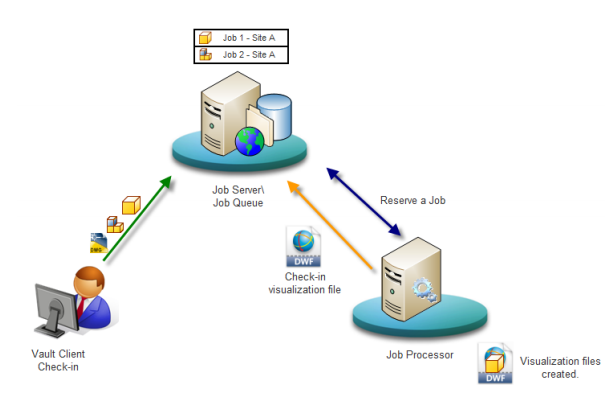
Job servers process jobs. They poll the job queue to determine if there’s work to do and if there is, they pop a job off the queue and execute it.
7. Full-text Search Service
Full-text search is the most common technique used in Web search engines and Web pages. Each page is searched and indexed, and if any matches are found, they are displayed via the indexes. Parts of original text are displayed against the user’s query and then the full text. Full-text search reduces the hassle of searching for a word in huge amounts of metadata.
Full Text Search provides extensive capabilities for natural-language querying. These include:
- Language-aware searching; allowing users to search for, say, the word ‘beauties’, and additionally obtain results for ‘beauty’ and ‘beautiful’
- Scoring of results, according to relevancy; allowing users to obtain result-sets that only contain documents awarded the highest scores. This keeps result-sets manageably small, even when the total number of documents returned is extremely large.
- Fast indexes, which support a wide range of possible text-searches.
Also Read | 5 Tips For Moving Your Team To Microservice Architecture
8. Web Services
A web service is a way for two applications or electronic devices to communicate over a network. Think of it like one human communicating with another human to provide a service.
E.g. If you need to convert American dollars to Euros, but you have no idea how. You turn to your friend, who happens to be from Belgium, and ask her to do the conversion for you.Now, you have the information you need while doing the minimal amount of work.
The interaction is much like a web service, acting as a means of quickly communicating important information between people the way a web service communicates information between electronic devices, applications, and other technologies.
Some of the standard methods of communication include:
- Extensible Markup Language (XML) is a way to label data so we can structure our information in meaningful ways.
- Web Services Description Language (WSDL) works as a help desk, describing the details of the web service.
- Universal Description, Discovery, and Integration (UDDI), – means of publishing and finding information about web services.
- Simple Object Access Protocol (SOAP) is like a courier or communicator during the transfer of data.
9. Data
Today, companies live and die based on how well they harness data. Almost every app these days, once it reaches a certain scale, leverages a data pipeline to ensure that data can be collected, stored, and analyzed. A typical pipeline has three main stages:
- The app sends data, typically events about user interactions, to the data “firehose” which provides a streaming interface to ingest and process the data. Often times the raw data is transformed or augmented and passed to another firehose. AWS Kinesis and Kafka are the two most common technologies for this purpose.
- The raw data as well as the final transformed/augmented data are saved to cloud storage. AWS Kinesis provides a setting called “firehose” that makes saving the raw data to it’s cloud storage (S3) extremely easy to configure.
- The transformed/augmented data is often loaded into a data warehouse for analysis. If the data sets are large enough, a Hadoop-like NoSQL MapReduce technology may be required for analysis.
10. Cloud Storage
Cloud storage is a service which lets you store data by transferring it over the Internet or another network to an offsite storage system maintained by a third party. There are hundreds of different cloud storage systems which include personal storage which holds and/or backs up emails, pictures, videos and other personal files of an individual, to enterprise storage.
These let businesses use cloud storage as a commercially-supported remote backup solution where the company can securely transfer and store data files or share them between locations.
Storage systems are typically scalable to suit an individual’s or organisation’s data storage needs, accessible from any location and are application-agnostic for accessibility from any device.
Businesses can select from three main models: a public cloud storage service which is suitable for unstructured data, a private cloud storage service which can be protected behind a company firewall for more control over data and a hybrid cloud storage service which blends public and private cloud services together for increased flexibility.
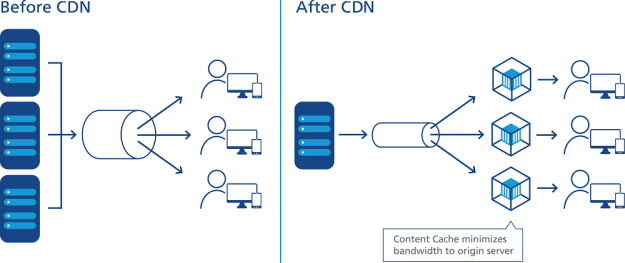
11. CDN
Content delivery networks are the transparent backbone of the Internet in charge of content delivery. Whether we know it or not, every one of us interacts with CDNs on a daily basis; when reading articles on news sites, shopping online, watching YouTube videos or perusing social media feeds.
You’ll find CDNs behind every character of text, every image pixel and every movie frame that gets delivered to your PC and mobile browser.
[spacer height=”20px”]
[spacer height=”20px”]
To minimize the distance between the visitors and your website’s server, a CDN stores a cached version of its content in multiple geographical locations (a.k.a., points of presence, or PoPs). Each PoP contains a number of caching servers responsible for content delivery to visitors within its proximity.
In essence, CDN puts your content in many places at once, providing superior coverage to your users. For example, when someone in London accesses your US-hosted website, it is done through a local UK PoP. This is much quicker than having the visitor’s requests, and your responses, travel the full width of the Atlantic and back.
[spacer height=”5px”][adrotate banner=”1″][spacer height=”5px”]
For powerful, feature rich, custom-built, native iOS or Android mobile app development click here
[spacer height=”5px”][adrotate banner=”2″][spacer height=”5px”]










